您现在的位置是:网站首页>内容内容
浅谈搜索引擎蜘蛛抓取网页规则_网站优化_网站运营_
![]() 2024-10-31 16:27:32
【512953070@qq.com】
182人已围观
2024-10-31 16:27:32
【512953070@qq.com】
182人已围观
简介 浅谈搜索引擎蜘蛛抓取网页规则_网站优化_网站运营_
一,爬虫框架
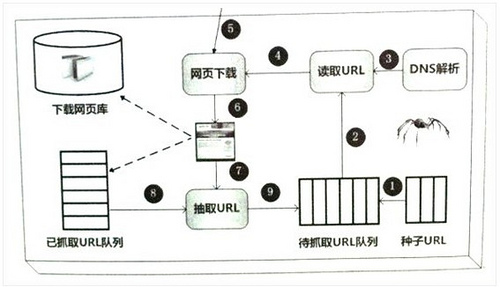
上图是一个简单的网络爬虫框架图。种子URL入手,如图所示,经过一步步的工作,最后将网页入库保存。当然,勤劳的蜘蛛可能需要做更多的工作,比如:网页去重以及网页反作弊等。
也许,我们可以将网页当作是蜘蛛的晚餐,晚餐包括:
已下载的网页。已经被蜘蛛抓取到的网页内容,放在肚子里了。
已过期网页。蜘蛛每次抓取的网页很多,有一些已经坏在肚子里了。
待下载网页。看到了食物,蜘蛛就要去抓取它。
可知网页。还没被下载和发现,但蜘蛛能够感觉到他们,早晚会去抓取它。
不可知网页。互联网太大,很多页面蜘蛛无法发现,可能永远也找不到,这部份占比很高。
通过以上划分,我们可以很清楚的理解搜索引擎蜘蛛的工作及面临的挑战。大多数蜘蛛是按照这样的框架去爬行。但也不完全一定,凡事总有特殊,根据职能的不同,蜘蛛系统存在一些差异。
二,爬虫类型
1,批量型蜘蛛。
这类蜘蛛有明确的抓取范围和目标,当蜘蛛完成目标和任务后就停止抓取。具体目标是什么?可能是抓取网页数量,网页大小,抓取时间等。
2,增量型蜘蛛
这类蜘蛛和批量型蜘蛛不同,他们会持续不断的抓取,对于抓取到的网页会定期抓取更新。因为互联网中的网页是随时处于更新状态中,增量型蜘蛛需要能够反映出这种更新。
3,垂直性蜘蛛
这种蜘蛛只关注特定主题或者特定的行业网页。以健康网站为例子,这类专门的蜘蛛会只抓取健康相关主题,其它主题内容的网页则不抓取。考验这只蜘蛛的难点是如何去更精准的识别内容所属于行业。目前来看,很多垂直类行业网站是需要这种蜘蛛去抓取的。
三,抓取策略
蜘蛛通过种子URL进行爬行拓展,列出大量待抓取URL。但是待抓取URL数量庞大,蜘蛛如何确定抓取顺序先后呢?蜘蛛抓取的策略有很多种,但最终目的是一 个:优先抓取重要的网页。评价页面是否重要,蜘蛛会根据页面内容原创程度,链接权重分析等众多方式来进行计算。比较有代表性的抓取策略如下:
1,宽度优先策略
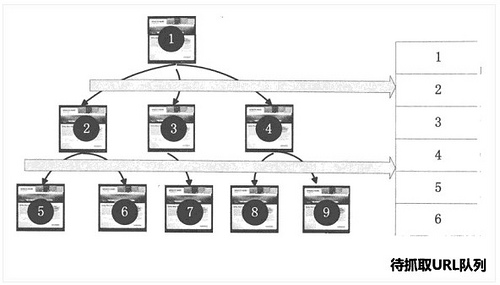
宽度优先是指:蜘蛛在抓取一个网页后,继续将该网页所包含的其它页面按顺序进行进一步抓取。这种思想看似简单,其实却很实用。因为大多数网页都是按优先级进行排序,重要的页面会优先在页面上进行推荐。
2,PageRank策略
PageRank是一种非常著名的链接分析方法,主要是用来衡量网页权重。如谷歌的PR,就是典型的PageRank算法。通过PageRank算法我们可以找出哪些页面是更重要的,然后蜘蛛优先去抓取这些重要性的页面。
3,大站优先策略
这个很容易理解,大网站通常拥有更多的内容页面,并且质量也会更高。蜘蛛会先分析网站归类与属性。如果这个网站已经收录很多,或者在搜索引擎系统中权重很高,则优先考虑收录。
四,网页更新
互联网中的页面大多会保持更新,这样就要求蜘蛛所存储的页面也能及时更新,保持一致性。打个比喻:一个网页之前排名很好,如果页面已经被删,却还有排名,那 体验就很不好。因此搜索引擎需要随时了解这些并更新页面,将最新的页面提供给用户。常用的网页更新策略在三种:历史参考策略,用户体验策略。聚类抽样策 略。
1,历史参考策略
这是建立在一种假设基础上的更新策略。比如,若你的网页之前按规律一直更新,那搜索引擎也认为你的页面将来也会经常更新,蜘蛛也会按这个规律定期来网站进行抓取网页。这也是为什么点水一直强调网站内容需要有规律更新的原因。
2,用户体验策略
一般来说,用户只会查看搜索结果前三页的内容,后面的页面很少有人去看。用户体验策略就是搜索引擎根据用户的这个特点来进行更新。例如,一个网页可能发布时 间较早,一段时间没更新,但是用户依然觉得有用,点击浏览它,那么搜索引擎先不去更新这些过时的网页也是可以的。这就是为什么搜索结果中,并不一定最新的 页面排名一定靠前的原因。排名更多的是取决于这个页面的质量,而完全不是更新时间先后。
3,聚类抽样策略
上两种更新策略主要是参考了网页的历史信息。但存储大量历史信息对搜索引擎来说是一种负担,另外如果收录的是新网页则是没有历史信息可以参考的,那怎么办? 聚类抽样策略是指:根据网页所展现出来的一些属性,来将很多相似网页进行归类,被归类的页面按照相同的规律去进行更新。
从了解搜索引擎蜘 蛛工作原理的过程中,我们会知道:网站内容之间的相关性,网站与网页内容更新规律,网页上链接分布以及网站权重高低等因素都会影响到蜘蛛的抓取效率。知已 知彼,让蜘蛛来得更猛烈些吧!




